In a previous tutorial we saw how to do an analysis of the coronavirus (covid19) outbreak using the dataset fetched from John Hopkins on Github. In this section we will see how to automatically fetch the new updated data daily ,prepare and clean the dataset for further analysis.
Since this is an ongoing study and new data are being collected and added daily it will be best for us to automate the process of fetching the data and cleaning the data.
We will be using two important python packages to help us achieve our aim – pandas and schedule.
Our main aim and task involves;
- Fetching the Dataset
- Cleaning and Preparing the Dataset
- How to Automate the entire process for daily updates
Fetching the Dataset
Our datasource is from this repo on Github which seems to be from John Hopkins university. Based on their terms of use, it is strictly for public use in academic or research purposes.
Okay, let us see how to fetch our dataset. There are several way we can do that.
Using Git
We can clone the entire repository using git or git-python(a python wrapper for git) and then use the dataset.
git clone https://github.com/CSSEGISandData/COVID-19.git
Using Pandas
With pandas you can actually get access to any dataset remotely and use it in your analysis by providing the direct URL path to your dataset. So in this case we will be using pandas read_csv() function to fetch our dataset. There will be 3 datasets we will be retrieving from github – Confirmed,Recovered and Deaths
confirmed_cases_url = "https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv" recovered_cases_url ="https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv" death_cases_url ="https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv"
We can then pass in to our read_csv() function our url.
import pandas as pd df = pd.read_csv(confirmed_cases_url)
After we have fetched our datasets we can then proceed to do our data cleaning or preparation.
Cleaning and Preparing Our Dataset
From previewing the dataset it looks like it is a timeseries sort of dataset hence we will need to restructure and reshape them to a format that we can easily analyse. We will be using pandas to melt it from a horizontal timeseries to a vertical timeseries as shown below.
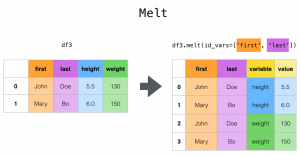
def get_n_melt_data(data_url,case_type):
df = pd.read_csv(data_url)
melted_df = df.melt(id_vars=['Province/State', 'Country/Region', 'Lat', 'Long'])
melted_df.rename(columns={"variable":"Date","value":case_type},inplace=True)
return melted_df
We will then join or merge our three dataset together using join. You can also use merge for the same purpose.
def merge_data(confirm_df,recovered_df,deaths_df): new_df = confirm_df.join(recovered_df['Recovered']).join(deaths_df['Deaths']) return new_df
Then we can then save our dataset and use it for our analysis.
How to Automate the Process
Since our dataset is updated almost daily it will be convenient to automate our process and schedule the entire task . Remember the famous rule of DRY – Don’t Repeat Yourself. If any task contains repetitive and predictable steps we can automate them to save our time.
We will be using schedule a python package for scheduling task – to automatically schedule our downloads and data cleaning task daily.
First of all let us install schedule
pip install schedule
With schedule you schedule any function per specific time or date just like with cron.
We will create a file “fetch_covid_data.py” and then put in all our code.
We will put all our task into a single function and then use it in schedule as below.
import time
import pandas as pd
import schedule
timestr = time.strftime("%Y%m%d-%H%M%S")
def fetch_data():
"""Fetch and Prep"""
confirm_df = get_n_melt_data(confirmed_cases_url,"Confirmed")
recovered_df = get_n_melt_data(recovered_cases_url,"Recovered")
deaths_df = get_n_melt_data(death_cases_url,"Deaths")
print("Merging Data")
final_df = merge_data(confirm_df,recovered_df,deaths_df)
print("Preview Data")
print(final_df.tail(5))
filename = "covid19_merged_dataset_updated_{}.csv".format(timestr)
print("Saving Dataset as {}".format(filename))
final_df.to_csv(filename,index='False')
print("Finished")
schedule.every().day.at("11:59").do(fetch_data)
while True:
schedule.run_pending()
time.sleep(1)
We can then run the script daily to do the entire process.
You can check the video tutorial here
To conclude we have seen how to fetch our data from a remote source, restructure and clean them and then automate and schedule the entire process. You can also convert this into a CLI if you want. To learn more about building CLI for such task you can check out this resource.
Thanks for your time and attention
Jesus Saves
By Jesse E.Agbe(JCharis)
Oh ,
It looks like not all of the datasets will be updated in the future. Only confirmed and deaths will be updated, but not recovered.
It looks so. Thanks Hodge