Machine Learning solutions depends on three main building blocks. This include
- Data
- Code
- Model
Machine learning solutions and products doesn’t end at just the development and training stage, even after deploying your ML solutions to production, you are still not done. This is because the world we live in is always changing and from this world we collect data to build our models. As such there is the need to monitor your ML solutions which consist of data,code and models for changes.
Changes any of these building blocks can influence the predictive prowess of your deployed model.
Data Drift
If there is changes in the data, we normally call it as Data Drift or Data Shift. A Data Drift can also refer to
- changes in the input data
- changes in the values of the features used to define or predict a target label.
- changes in the properties of the independent variable
Model Drift
This refers to changes in the performance of the model over time. It is the deterioration of models over time in the case of accuracy and prediction.ML Models do not live in a static environment hence they will deteriorate or decay over time.
Since Models depend on Data, any change in data will eventually affect the model. Because of this we can simplify or classify all the changes of either data and model into these types
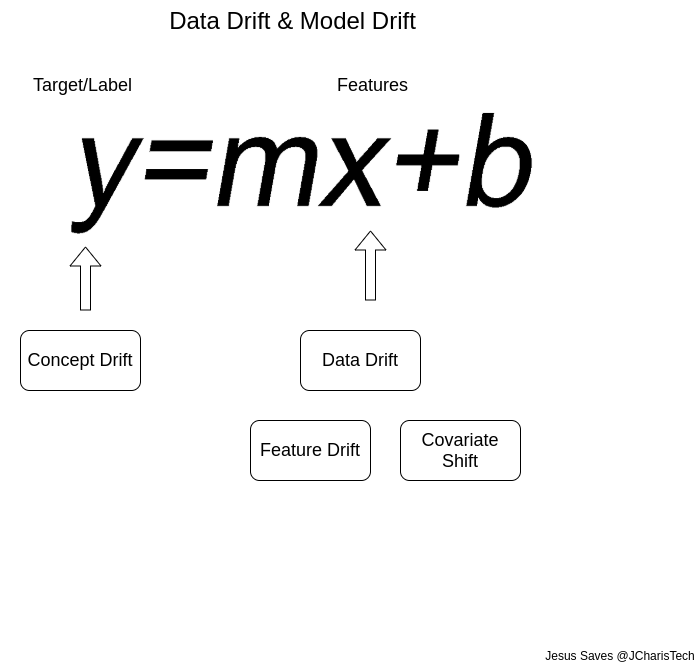
Types of Drift
Data Drift
- Feature Drift/Shift: changes in the independent features/variables. Examples of data drift include changes in the data due to seasonality, changes in consumer preferences, the addition of new products, etc…
- Covariate Shift: this refers to changes in the distribution of one or more of the independent variables or input variables of the dataset. This means that even though the relationship between feature and target variable remains unchanged, and how our feature is correlated with our labels remains the same, the distribution of the feature itself has changed.
- Suppose a model is trained with several variables with one being an age variable that ranges from 20 years to 50 years and is in production. Over time, if the ages increases and the model encounters real-time data where the ages are above 50 let say 55 years, 60yrs etc. Our model will see an increase in mean and variance, and therefore it leads to a untrustworthy predictions.
- Concept drift: it is a type of drift where the properties of the dependent variable changes. In a cause of fraudulent detection model, if what we mean by ‘fraudulent’ changes, then our concept of what we mean by fraud has changed and therefore we have concept drift. Any changes to the properties of the target/label mostly due to external factors can be termed as concept drift.
That is the properties of the target variable, which the model is trying to predict, has changed over time. In a way it can be seen as a form of label drift or target drift.
Upstream data changes refer to operational data changes in the data pipeline. An example of this is when a feature is no longer being generated, resulting in missing values. Another example is a change in measurement (eg. miles to kilometers).
In summary we can have
- Data Drift
- Feature Drift
- Covariate Shift
- Upstream data changes
- Model Drift
- Concept Drift
- Prediction Drift
Tools For Detecting Data Drift
So how do you detect data drift and model drift. Below are some of the tools used to detect drift.
- MLFlow
- WandB
- Scikit-multiflow (ADWIN)
- River (online ML)
- Deepchecks (a collection of suites for data drift detection)
- Evidently.ai
- Pachyderm
- Prometheus
- Custom functions
In the upcoming post we will pick some of them and explore how they are used for data drift detection
Ways to Fix Data Drift & Model Drift.
There are several ways we can use to fix this issue. After detecting a drift via model monitoring the simplest method is to retrain the model with recent and relevant data. However you can use the following methods concerning the model drift
- Retraining of Model
- Use of Streaming Models or Incremental ML such as Spark Streaming,Creme/River,etc
- Use of adaptive ensemble methods that adapts to changing data
- Periodic update of canary model using the previous model as the starting point without discarding it. This is good for regression models.
For data drift, you can prepare the data in such a way to deal with seasonal or unexpected changes. Mostly good for Time Series forecasting where by you may use ARIMA.
A Simple Way to Detect Data Drift using Deepchecks
Deepchecks is a python library that can be used for detecting data drift,data integrity,model performance and more. It offers a lot out of the box so we can easily use this tool for detecting data drift. It is good for offline model drift detection
Installation
pip install deepchecksTo simplify the usage of deepcheck and what it does I have simplified it to three main features or classes. These include
- Suites: a collection of functions for model evaluation,data integrity,data drift,etc
- Checks: for data drift,label drift,feature drift and trust score for model confidence
- Dataset: a class for building datasets to be used by Deepchecks.
Full Suites
The full suite is the simplest one in all feature for everything. We can use it as below
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import deepchecks
from deepchecks.suites import full_suite
# load data
df = pd.read_csv("mydata.csv")
# Split Dataset
# Features & Labels
Xfeatures = df.drop('label',axis=1)
# Select last column of dataframe as a dataframe object
ylabels = df.iloc[: , -1:]
x_train,x_test,y_train,y_test = train_test_split(Xfeatures,ylabels,test_size=0.3,random_state=7)
# Build Model
model = LogisticRegression()
model.fit(x_train,y_train)
# Prepare data for Deepchecks
ds_train = deepchecks.Dataset(df=x_train,label=y_train)
ds_test = deepchecks.Dataset(df=x_test,label=y_test)
# Full Suite
suite = full_suite()
result = suite.run(train_dataset=ds_train,test_dataset=ds_test,model=model)
result Checking For Feature Drift
You can use deepchecks to detect for Feature Drift via
from deepchecks.checks import TrainTestFeatureDrift
check = TrainTestFeatureDrift()
result = check.run(train_dataset=ds_train, test_dataset=ds_test, model=pipe_lr)Checking For Label Drift
You can use deepchecks to detect for Label Drift without adding the model via
from deepchecks.checks import TrainTestLabelDrift
check = TrainTestLabelDrift()
result = check.run(train_dataset=ds_train, test_dataset=ds_test)There are other things we can also do.
To conclude we have learn about Data Drift and Model drift and how to use some tools to detect drift in our data for our ML products.
You can check out the video tutorial for more.
Thanks For Your Time
Jesus Saves
By Jesse E.Agbe(JCharis)