
In this tutorial we will be building a document redaction app. Document redaction refers to the process of sanitizing and censoring a document based on selected terms. It is one of the applications of NLP – natural language processing.
This image shows some of it use. In this case the important terms have been blacked out or censored.

We will be learning how to use spacy’s named entities recognition to perform document redaction and censorship. The basic approach is as follows
- Extract Named Entities with SpaCy
- Select The Entity Type we want to sanitize
- Replace the Selected Token with [‘REDACTED’]
- Join The Tokenized Text together.
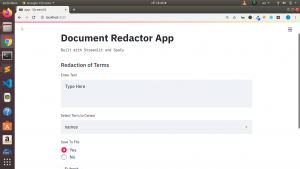
Let us see what we will be building
For more on building NLP and ML web apps you can check out these links.
Let us begin
Installation
We will be using the following packages
pip install streamlit spacy
To begin with we will import our necessary packages
# Core Packages
import streamlit as st
import os
import base64
#NLP Pkgs
import spacy
from spacy import displacy
nlp = spacy.load('en')
# Time Pkg
import time
timestr = time.strftime("%Y%m%d-%H%M%S")
We will have individual functions to sanitize our text based on the term we select and a function to write our result to a file as well as one to make our saved result downloadable.
For rendering the Named Entities we will wrap it within an html tag template as below
HTML_WRAPPER = """<div style="overflow-x: auto; border: 1px solid #e6e9ef; border-radius: 0.25rem; padding: 1rem">{}</div>"""
This is to add beauty and style to our named entities.
# Functions to Sanitize and Redact
def sanitize_names(text):
docx = nlp(text)
redacted_sentences = []
for ent in docx.ents:
ent.merge()
for token in docx:
if token.ent_type_ == 'PERSON':
redacted_sentences.append("[REDACTED NAME]")
else:
redacted_sentences.append(token.string)
return "".join(redacted_sentences)
def sanitize_places(text):
docx = nlp(text)
redacted_sentences = []
for ent in docx.ents:
ent.merge()
for token in docx:
if token.ent_type_ == 'GPE':
redacted_sentences.append("[REDACTED PLACE]")
else:
redacted_sentences.append(token.string)
return "".join(redacted_sentences)
def sanitize_date(text):
docx = nlp(text)
redacted_sentences = []
for ent in docx.ents:
ent.merge()
for token in docx:
if token.ent_type_ == 'DATE':
redacted_sentences.append("[REDACTED DATE]")
else:
redacted_sentences.append(token.string)
return "".join(redacted_sentences)
def sanitize_org(text):
docx = nlp(text)
redacted_sentences = []
for ent in docx.ents:
ent.merge()
for token in docx:
if token.ent_type_ == 'ORG':
redacted_sentences.append("[REDACTED]")
else:
redacted_sentences.append(token.string)
return "".join(redacted_sentences)
def writetofile(text,file_name):
with open(os.path.join('downloads',file_name),'w') as f:
f.write(text)
return file_name
def make_downloadable(filename):
readfile = open(os.path.join("downloads",filename)).read()
b64 = base64.b64encode(readfile.encode()).decode()
href = 'Download File File (right-click and save as <some_name>.txt)'.format(b64)
return href
Do make the download work we will be using st.markdown() and set unsafe_allow_html to True. Since for now there is no file download option for streamlit hence we will use a workaround made by @MarcSkovMadsen of awesomestreamlit.org. He utilized base64 and html anchor tags to make this work.
Then we will create a main function in which we will include all our activities. We will have three main activities in our sidebar- Redaction,Downloads and About.
The entire code for the main function is as follows.
def main():
"""Document Redaction with Streamlit"""
st.title("Document Redactor App")
st.text("Built with Streamlit and SpaCy")
activities = ["Redaction","Downloads","About"]
choice = st.sidebar.selectbox("Select Choice",activities)
if choice == 'Redaction':
st.subheader("Redaction of Terms")
rawtext = st.text_area("Enter Text","Type Here")
redaction_item = ["names","places","org","date"]
redaction_choice = st.selectbox("Select Item to Censor",redaction_item)
save_option = st.radio("Save to File",("Yes","No"))
if st.button("Submit"):
if save_option == 'Yes':
if redaction_choice == 'redact_names':
result = sanitize_names(rawtext)
elif redaction_choice == 'places':
result = sanitize_places(rawtext)
elif redaction_choice == 'date':
result = sanitize_date(rawtext)
elif redaction_choice == 'org':
result = sanitize_org(rawtext)
else:
result = sanitize_names(rawtext)
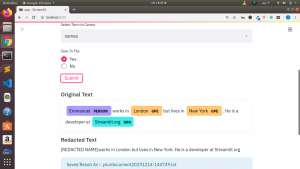
st.subheader("Original Text")
new_docx = render_entities(rawtext)
st.markdown(new_docx,unsafe_allow_html=True)
st.subheader("Redacted Text")
st.write(result)
file_to_download = writetofile(result,file_name)
st.info("Saved Result As :: {}".format(file_name))
d_link = make_downloadable(file_to_download)
st.markdown(d_link,unsafe_allow_html=True)
else:
if redaction_choice == 'redact_names':
result = sanitize_names(rawtext)
elif redaction_choice == 'places':
result = sanitize_places(rawtext)
elif redaction_choice == 'date':
result = sanitize_date(rawtext)
elif redaction_choice == 'org':
result = sanitize_org(rawtext)
else:
result = sanitize_names(rawtext)
st.write(result)
elif choice == 'Downloads':
st.subheader("Downloads List")
files = os.listdir(os.path.join('downloads'))
file_to_download = st.selectbox("Select File To Download",files)
st.info("File Name: {}".format(file_to_download))
d_link = make_downloadable(file_to_download)
st.markdown(d_link,unsafe_allow_html=True)
elif choice == 'About':
st.subheader("About The App & Credits ")
st.text("MarcSkovMadsen @awesomestreamlit.org")
st.text("Adrien Treuille @streamlit")
st.text("Jesse E.Agbe @JCharisTech")
st.success("Jesus Saves@JCharisTech")
if __name__ == '__main__':
main()
You can then run the app with
streamlit run app.py
Viola, Streamlit makes it easy to build a production ready NLP app with ease
You can also check the video tutorial here.
Thanks For Your Time
Jesus Saves
By Jesse E.Agbe(JCharis)
new_docx = render_entities(rawtext)
getting the error “NameError: name ‘render_entities’ is not defined”
Help me to solve this error.
Hi Joseph, you will need to define that function render_entities() before.
This will fix it. Hope it helps
Hi Jesse… Thanks for the reply.
I just followed your code.
Is render_entities() function needed any package?
Hope this is not an user defined function.
Need some clarity please.
Yes Joseph, it is a user defined custom function and it relies on spacy’s NER.
Hope it helps
Code works in Jupyter Notebook?