
Streamlit makes it quite easy and simple to build production ready data science apps (or Data Apps). In this post we will see how to deploy a simple app that uses some NLP packages such as Spacy and TextBlob on Streamlit Sharing.
By the end of this post, you will learn
- How to generate requirements.txt file
- How to add models and corpora to your requirements.txt file
- How to deploy data apps on streamlit sharing
- How to fix issues when deploying your streamlit apps
Most NLP apps requires you to work with the NLP library such as Spacy or NLTK or TextBlob which depends on an additional model or corpora. These models or corpora is used by the library when performing some text analysis such as Named Entity Recognition or Parts of Speech tagging. These models are pretrained models that the developers of the said library have already serialized to be used in the library.
On your local system, it is easier to work with it by downloading the package and then the serialized model or file .
For example with Spacy you can do
pip install spacy
Then download the pretrained model via
python3 -m spacy download en
For TextBlob you will also have to do likewise
pip install textblob python3 -m textblob.download_corpora
Just like the local system, you can also specify the same code in your Dockerfile when deploying your apps with docker in a container.
However the case is different when deploying your app on streamlit sharing or heroku, where by you are not using a Dockerfile but rather only a requirements.txt file or packages.txt file. Let us see how to work with it and the issues we will encounter and how to fix them
Deploying on Streamlit Sharing

As show above the requirements for deploying on streamlit sharing is
- Your streamlit app.py file
- requirements.txt file: which contains what your app depends upon
- Host on Github as Public Repositiory
- Account on Share.streamlit.io
How to Get Requirements.txt File
There are several was we can get the requirements.txt file such as using
pip freeze > requirements.txt file
or with pipenv and pipfile
But the simplest is to use pipreqs package. This makes it easier to generate your requirements.txt file by just pointing to the folder with your python script example.
pipreqs myapp_folder/
Now having generated our requirements.txt file we can now push our app to Github and then add to our share.streamlit.io apps and boom our app has been deployed. Simple as that.
However that is not the case for an app that uses pretrained models or serialized files such as Spacy or TextBlob. You will meet our first challenge
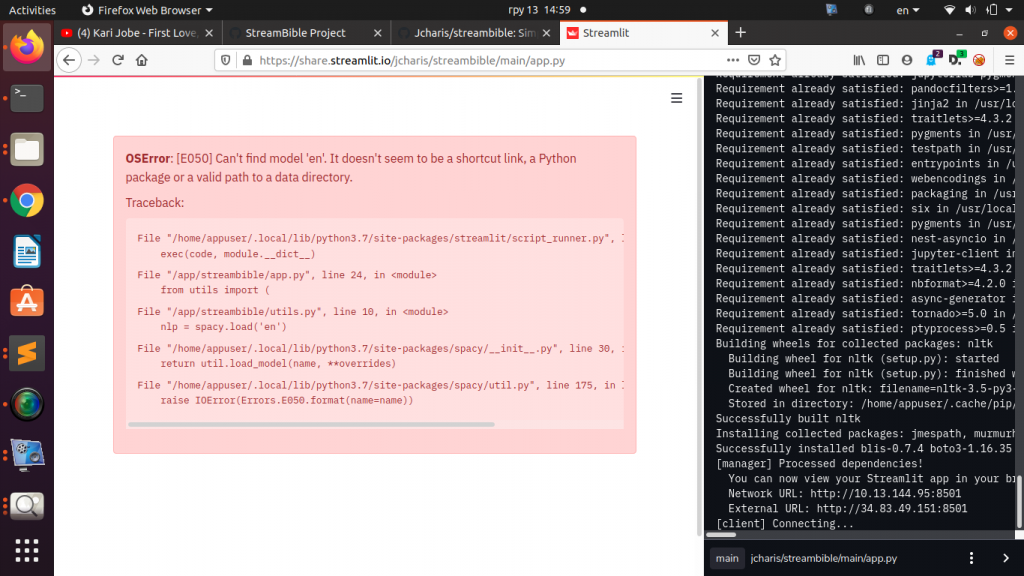
There is an OSError and we can’t find the model ‘en’ used by spacy. So how do you fix this issue.
Fixing the OSError model ‘en’ Not found
To fix this issue you will have to change the name of ‘en‘ to the full name of the Spacy Model in your app to ‘en_core_web_sm‘
import spacy
nlp = spacy.load('en_core_web_sm') # instead of spacy.load('en')
Next you will have to include this model in your requirements.txt file so that it will be downloaded to your workspace. You will have to add this
spacy>=2.2.0,<3.0.0 https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-2.2.0/en_core_web_sm-2.2.0.tar.gz#egg=en_core_web_sm
This will fix the issue for Spacy for our app.
Now what about TextBlob and NLTK .
Fixing TextBlob & NLTK Corpora Issues
Unlike textblob and nltk you cannot include their corpora in the requirements.txt file since they are stored in a different place. Hence you will have to use a different approach.
Let us see how to fix this.
The simple work around is to create another python scripts and use subprocess or os.system to run the required command to download the needed corpora.
So using this code you can download the required corpora when you deploy your app on streamlit sharing.
For TextBlob
import subprocess
cmd = ['python3','-m','textblob.download_corpora']
subprocess.run(cmd)
print("Working")
For NLTK Corpora
You can create a simple file “nltk_download_utils.py” and place in the following code
import nltk
nltk.download('wordnet')
nltk.download('punkt')
nltk.download('all-corpora')
And then import this nltk_download_utils in your main app.py file to download this files.
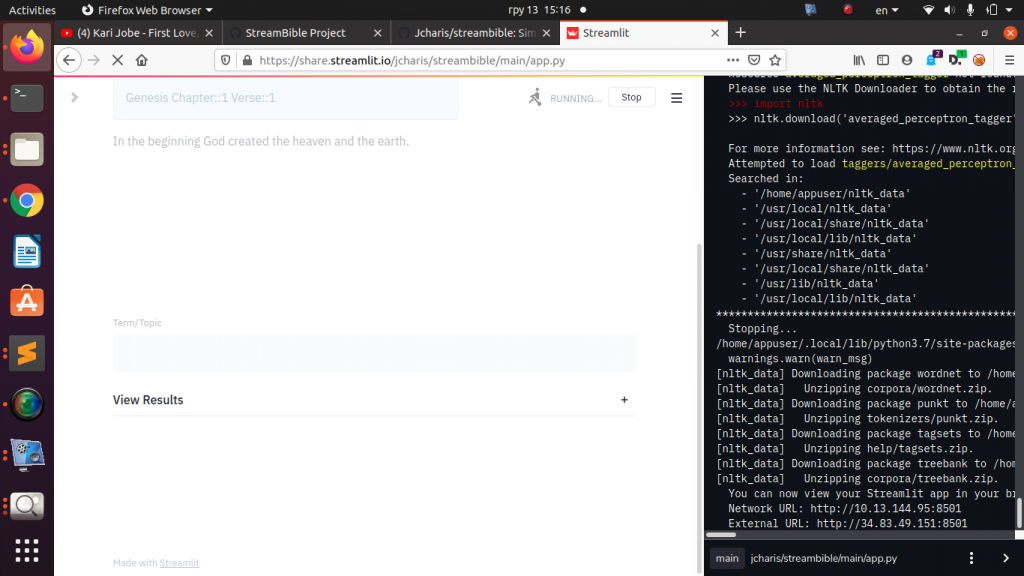
This will fix the issue.
To recap we have seen how to generate requirements.txt file and how to include the option to download spacy pretrained model withing our requirements.txt
We have also seen how to fix issues with textblob corpora and nltk corpora.
You can check out the video tutorial and more resources on streamlit here.
Thanks For Your Time
Jesus Saves
By Jesse E.Agbe(JCharis)