The normal everyday data science/ML workflow follows a particular pattern of taking in data, analyzing the data and then deriving useful insights to build problem solving and predictive tools.
One of the simplest and most useful ways of working with such a workflow is to use pipelines. So what is a Pipeline? Why is it important and how do we build one?
By the end of this tutorial we will learn about
- What a pipeline is?
- Types of Pipelines
- Stages of an ML Pipeline
- How to build an ML Pipeline using Scikit-Learn
- How to build an EDA Pipeline
- etc
What is a Pipeline?
A Pipeline consists of a chain of processing elements or functions arranged so that the output of each element is the input of the next. It is a way of chaining functions and task to that are usually in a workflow. It is a means of automating a workflow.
It is used in several fields such as Data Science, Machine Learning and DevOps ,Manufacturing as well as General Software development.
It is a continuous life cycle similar to how an assembly line works in the manufacturing industry.
In brief a A Machine Learning Pipeline refers to
- A means of automating the ML workflow
- A way to codify and automate how we produce a usable ML model
- An independently executable workflow of a complete ML task
- The act of executing task in sequence automatically
- Use to package workflows or sequence of tasks
A Pipeline is simply a means used to package a sequence of tasks and functions in such a way that makes it reproducible and convenient to manage.
Advantages of Using ML Pipelines
- It makes building models more efficient and simplified
- Helps cut redundant work
- Moves the product from just the model to the pipeline/workflow and this improves efficiency
and scalability - Easy to monitor each components/stage
- Fast iteration cycle
- A Pipeline reduces the chance of error and saves time by automating repetitive tasks.
- Allows you to monitor and tune processes
In this tutorial we will talk about two main Pipelines precisely an EDA pipeline and an ML Pipeline
Let us start with the ML Pipeline.
Types of Pipelines
There are several pipelines used in any Data Science Project. These types of pipeline depends on
the problem and task at hand. This determines the kind of pipeline we can have therefore based on the field we can have
- ETL/EDA Pipeline
- NLP Pipeline
- ML Pipeline
- CI/CD Pipeline
Most frameworks allows us to build pipelines when performing a project. We will explore how to use Scikit-Learn to build pipelines that take in data ,transforms the data and produces a working model.
Stages of an ML Pipeline(Scikit-Learn Pipeline)
In building an ML Pipeline using scikit-learn, you will have to know the main components or stages.
Every ML Pipeline consist of several tasks which can be classified based on their input to output
flow.
Based on that we can have two main stages of an ML Pipeline which includes
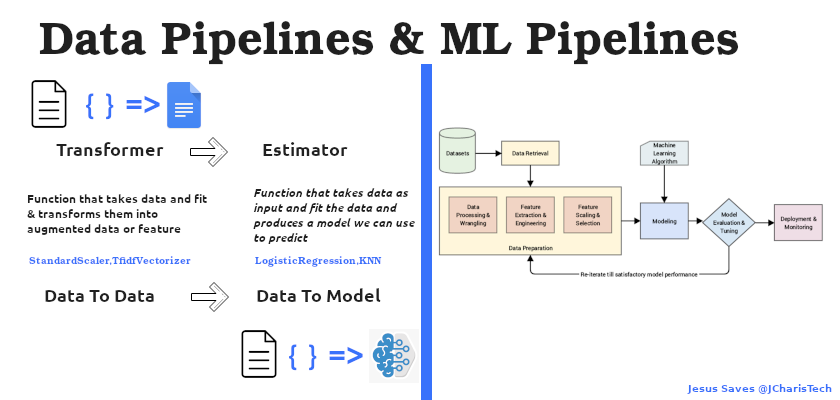
- Data to Data Pipeline
- Data to Model Pipeline
So what do these mean?
Data To Data Pipeline(Transformer Stage)
- This involves the stage in which we take in or ingest data and then produce as an output
data. - The main concept here is via the use of Transformers.
- A Transformer a function that takes in data as input and convert/transforms that data into another form of data that is usually augmented or feature ready.
- This starts from data ingestion to data cleaning to data transformation and verification as well as feature engineering
Data to Model Pipeline(Estimator Stage)
- This is the stage in which we take in data (usually a prepared data) as input and then
learns from it to produce a model. - We take in data and using an Estimator we fit the data and build a model that can be
used on other dataset to perform predictive task - The main concept here is via the use of Estimators
∗ An Estimator is a function that fit data and yields a model
∗ eg All the ML Algorithms such as KNN, Logistic Regression,MLP etc
Scikit-learn – a popular machine learning library allows data scientist and ML engineers to build pipelines for their project. It offers the sklearn.pipeline subpackage to help us build pipelines.
Let us see how to build a pipeline in code using scikit-learn. We will first import our packages .
##### Estimators
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier##### Transformers
from sklearn.preprocessing import StandardScaler,MinMaxScaler
##### Utils
from sklearn.model_selection import train_test_split
from sklearn.pipeline import PipelineWe will create a pipeline consisting of one transformer (StandardScaler) and one ML estimator(LogisticRegression) . There are two ways of creating a pipeline either using the Pipeline() Constructor or the make_pipeline() function
pipe_lr = Pipeline([
('scaler',StandardScaler()),
('lr',LogisticRegression())
])Alternatively we can use the make_pipeline() like this.
from sklearn.pipeline import make_pipeline
new_pipe_lr = make_pipeline(StandardScaler(),LogisticRegression())
>>>new_pipe_lr
Pipeline(steps=[('standardscaler', StandardScaler()),
('logisticregression', LogisticRegression())])We can now fit our pipeline on our data to performing our training
pipe_lr = pipe_lr.fit(X_train, y_train)You can also get the steps and the stages of the pipeline using the pipe.steps or pipe.named_steps such as
#### Get the steps
pipe_lr.steps#### Get the steps as a Dictionary
pipe_lr.named_stepsTo get the parameters of a stage/step be it a transformer or estimator you can use pipe.get_params()
#### Get Params of A step
##### [stringlabel][estimator/transformer]
pipe_lr.steps[0][1].get_params()You can also get the all the parameters of a pipeline
##### Get Params of Entire Pipeline and Details
pipe_lr.get_params()You can now use your pipe to make prediction and even get the accuracy score
print('Accuracy score: ', pipe_lr.score(X_test, y_test))
To Make a prediction you can use the pipe.predict(yoursample)
pipe_lr.predict(sample)
pipe_lr.predict_proba(sample)To conclude we have seen how to build ML pipelines using scikit-learn. A pipeline can also consist of only transformers or transformers and estimators.
You can also check out the video tutorial below.
Thank You For Your Time
Jesus Saves
By Jesse E.Agbe(JCharis)