
In today’s tutorial we will be exploring another powerful natural language processing library called Flair. We will be seeing how to use Flair for text classification. Specifically we will learn how to build a model to predict or classify text as either offensive or non-offensive.
What is Flair?
Flair is a state of the art(SOTA) NLP Library built on top of Pytorch which useful for performing several natural language processing task such as
- Sequence Labeling
- Text/Linguistic Annotation
- Named Entity Recognition
- Tagging
- Text Classification and Sentiment Analysis
- Semantic Frame Detection
- etc
It is also known in the Biomedical field as a BioMedical NER Library via using SciSpacy and several pretrained models.
Basic Overview of Flair
The basic overview of Flair includes the following
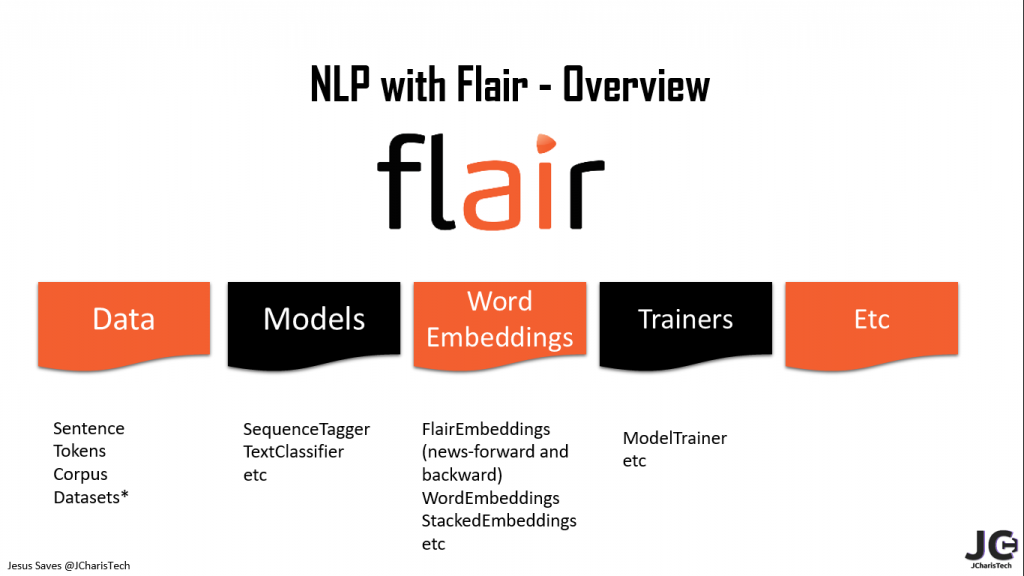
Let us see how to work with Flair
Installation
To work with flair , you can install it using pip as below
pip install flair
You can also try Flair inside Google’s Colab for simplicity.
Let us move on to our main task – Text Classification using Flair.
To explore more on NLP with Flair you can check out this course.
Text Classification with Flair
Text classification is one of the most useful and common applications of Natural Language Processing. It involves the process of identifying or grouping text into their specific class or categories. There are several ways we can achieve this process but in our case we will be training our own ML model to classify our text as either offensive or non-offensive.
Let us check the simple workflow for performing text classification with Flair
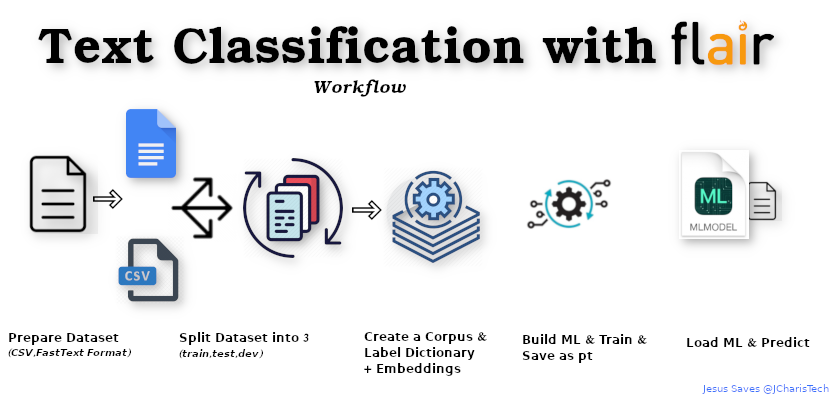
It is essential to understand this in order to make it easier for us in this task.
There are basically 6 steps
- Step1: Prepare Dataset ( as either csv, or fastText format)
- Step2: Split the dataset into 3 (train,test,dev)
- Step3: Create Corpus and Label Dictionary
- Step4: Add Word Embeddings
- Step5: Instantiate Model and Train using the data
- Step6: Use Model to Make Prediction
Preparing Dataset
As we always do we will have to clean our textual dataset to remove noisy,punctuations and special characters. You can simplify this process using the NeatText text cleaning package. Noticed that we have already cleaned our dataset to make it easier for us. Hence we will be using the cleaned dataset (easy)
Now in preparing the dataset, we can use the normal csv format or the FastText format. The FastText format follows the pattern of using
`__label__<class> <text>`
But you can also use the normal dataset in csv format, the only difference is that you will have to use the CSVClassificationCorpus when building your corpus for the training instead of the ClassificationCorpus for the FastText format.
Splitting the Dataset into 3
One of the requirement for working with Flair for text classification and model building is to have 3 dataset named as train.csv,test.csv,dev.csv (.txt if you are using fasttext format). These are to ensure that we have data for training,testing and validating when we are building the ML model.
We will be using numpy to help us do the splitting but you can also use train_test_split from sklearn if you want. Numpy has a simple function for splitting data/arrays into proportions as you want – the np.split() function.
Creating our Corpus and Label Dictionary
In creating the corpus you can use the CSVClassificationCorpus (for the CSV) and the ClassificationCorpus(for the fastText format) alongside the 3 splitted datasets
Word Embeddings
Flair offers the option of using several word embedding as you want. You can even use the word embeddings from Flair – FlairEmbedding. You can also stack different word embeddings together.
We will ten proceed to build and train our model respectively.
You can check out the code below
In [4]:
# Load EDA Pkgs import pandas as pd import numpy as np
In [5]:
df = pd.read_csv("offensive_vs_non_offensive_mini_dataset.csv")
In [6]:
df.head()
Out[6]:
| Unnamed: 0 | clean_tweet | class | labels | |
|---|---|---|---|---|
| 0 | 0 | look at what you just said lls new era girl … | 1 | offensive |
| 1 | 1 | driving the fucktardmobile tranny slips and a… | 1 | offensive |
| 2 | 2 | if i ever put ma trust ina bitch i will alwa… | 1 | offensive |
| 3 | 3 | stop twatching me bitch | 1 | offensive |
| 4 | 4 | you know bitches be mad when they be lik… | 1 | offensive |
In [7]:
# Check for value count df['class'].value_counts()
Out[7]:
1 3850 0 821 Name: class, dtype: int64
In [8]:
import seaborn as sns
In [9]:
sns.countplot(df['class'])
/usr/local/lib/python3.6/dist-packages/seaborn/_decorators.py:43: FutureWarning: Pass the following variable as a keyword arg: x. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation. FutureWarning
Out[9]:
<matplotlib.axes._subplots.AxesSubplot at 0x7f52ed97eeb8>
In [10]:
# Preparing Dataset # Using CSV df.head()
Out[10]:
| Unnamed: 0 | clean_tweet | class | labels | |
|---|---|---|---|---|
| 0 | 0 | look at what you just said lls new era girl … | 1 | offensive |
| 1 | 1 | driving the fucktardmobile tranny slips and a… | 1 | offensive |
| 2 | 2 | if i ever put ma trust ina bitch i will alwa… | 1 | offensive |
| 3 | 3 | stop twatching me bitch | 1 | offensive |
| 4 | 4 | you know bitches be mad when they be lik… | 1 | offensive |
In [11]:
df.columns
Out[11]:
Index(['Unnamed: 0', 'clean_tweet', 'class', 'labels'], dtype='object')
In [12]:
df1 = df[['clean_tweet','labels']]
In [14]:
# Rename Columns df1.columns = ['text','labels']
In [15]:
df1
Out[15]:
| text | labels | |
|---|---|---|
| 0 | look at what you just said lls new era girl … | offensive |
| 1 | driving the fucktardmobile tranny slips and a… | offensive |
| 2 | if i ever put ma trust ina bitch i will alwa… | offensive |
| 3 | stop twatching me bitch | offensive |
| 4 | you know bitches be mad when they be lik… | offensive |
| … | … | … |
| 4666 | this bitch gonna steal a police uniform and th… | offensive |
| 4667 | if california chrome does not go off at even m… | offensive |
| 4668 | i do not love you hoes | offensive |
| 4669 | lmaoooo white people lmaoo filth … | offensive |
| 4670 | if you really wanna please your man seeing… | offensive |
4671 rows × 2 columns In [16]:
# Prepare for FastText Format #__label__ <class> <text> df1.head()
Out[16]:
| text | labels | |
|---|---|---|
| 0 | look at what you just said lls new era girl … | offensive |
| 1 | driving the fucktardmobile tranny slips and a… | offensive |
| 2 | if i ever put ma trust ina bitch i will alwa… | offensive |
| 3 | stop twatching me bitch | offensive |
| 4 | you know bitches be mad when they be lik… | offensive |
In [17]:
# For FastText df_fst = df1.copy()
In [18]:
df_fst.head()
Out[18]:
| text | labels | |
|---|---|---|
| 0 | look at what you just said lls new era girl … | offensive |
| 1 | driving the fucktardmobile tranny slips and a… | offensive |
| 2 | if i ever put ma trust ina bitch i will alwa… | offensive |
| 3 | stop twatching me bitch | offensive |
| 4 | you know bitches be mad when they be lik… | offensive |
In [19]:
'__label__' + df_fst['labels'].astype(str)
Out[19]:
0 __label__offensive
1 __label__offensive
2 __label__offensive
3 __label__offensive
4 __label__offensive
...
4666 __label__offensive
4667 __label__offensive
4668 __label__offensive
4669 __label__offensive
4670 __label__offensive
Name: labels, Length: 4671, dtype: object
In [20]:
df_fst['labels'] = '__label__' + df_fst['labels'].astype(str)
In [22]:
df_fst = df_fst[['labels','text']]
In [ ]:
### Spliting Dataset into 3 ### train,test,dev.csv #### 60,20,20
In [24]:
# Using Numpy train,test,dev = np.split(df1,[int(.6*len(df1)),int(.8*len(df1))])
In [26]:
print(df1.shape) print(train.shape) print(test.shape) print(dev.shape)
(4671, 2) (2802, 2) (934, 2) (935, 2)
In [27]:
# Create A Folder for the csv !mkdir -p data
In [28]:
train.to_csv("data/train.csv")
test.to_csv("data/test.csv")
dev.to_csv("data/dev.csv")
In [29]:
!ls data
dev.csv test.csv train.csv
In [30]:
df_fst
Out[30]:
| labels | text | |
|---|---|---|
| 0 | __label__offensive | look at what you just said lls new era girl … |
| 1 | __label__offensive | driving the fucktardmobile tranny slips and a… |
| 2 | __label__offensive | if i ever put ma trust ina bitch i will alwa… |
| 3 | __label__offensive | stop twatching me bitch |
| 4 | __label__offensive | you know bitches be mad when they be lik… |
| … | … | … |
| 4666 | __label__offensive | this bitch gonna steal a police uniform and th… |
| 4667 | __label__offensive | if california chrome does not go off at even m… |
| 4668 | __label__offensive | i do not love you hoes |
| 4669 | __label__offensive | lmaoooo white people lmaoo filth … |
| 4670 | __label__offensive | if you really wanna please your man seeing… |
4671 rows × 2 columns In [31]:
# Spliting FastText Format Dataset into 3 # Using Numpy train_fst,test_fst,dev_fst = np.split(df_fst,[int(.6*len(df_fst)),int(.8*len(df_fst))])
In [32]:
# Store in a folder !mkdir -p data_fst
In [33]:
train_fst.to_csv("data_fst/train.csv",sep='\t',index=False,header=False)
test_fst.to_csv("data_fst/test.csv",sep='\t',index=False,header=False)
dev_fst.to_csv("data_fst/dev.csv",sep='\t',index=False,header=False)
In [34]:
!ls data_fst
dev.csv test.csv train.csv
In [ ]:
### Building our Corpus # CSVClassificationCorpus # ClassificationCorpus
In [35]:
from flair.datasets import ClassificationCorpus,CSVClassificationCorpus from flair.data import Corpus
In [36]:
# For CSV df1.columns
Out[36]:
Index(['text', 'labels'], dtype='object')
In [55]:
# Create Column Mapping to show which column is for label and text
column_name_map = {2:"label_topic",1:"text"}
In [39]:
# Location for CSV data_folder = 'data/'
In [56]:
# Create Corpus For CSV corpus_csv: Corpus = CSVClassificationCorpus(data_folder,column_name_map=column_name_map,skip_header=True,delimiter=',')
2020-10-04 13:59:26,410 Reading data from data 2020-10-04 13:59:26,414 Train: data/train.csv 2020-10-04 13:59:26,416 Dev: data/dev.csv 2020-10-04 13:59:26,417 Test: data/test.csv
In [41]:
# Method 2 Using FastText Format data_folder_fst = 'data_fst/'
In [42]:
corpus_fst: Corpus = ClassificationCorpus(data_folder_fst)
2020-10-04 13:32:54,135 Reading data from data_fst 2020-10-04 13:32:54,137 Train: data_fst/train.csv 2020-10-04 13:32:54,138 Dev: data_fst/dev.csv 2020-10-04 13:32:54,139 Test: data_fst/test.csv
In [57]:
# Creating the Label Diction For CSV label_dict_csv = corpus_csv.make_label_dictionary()
2020-10-04 13:59:43,582 Computing label dictionary. Progress:
100%|██████████| 3736/3736 [00:02<00:00, 1383.38it/s]
2020-10-04 13:59:46,550 [b'offensive', b'non_offensive']
In [44]:
# Creating the Label Diction For FastText label_dict_fst = corpus_fst.make_label_dictionary()
2020-10-04 13:34:57,415 Computing label dictionary. Progress:
100%|██████████| 3733/3733 [00:02<00:00, 1827.83it/s]
2020-10-04 13:34:59,588 [b'offensive', b'non_offensive']
In [45]:
# Working with the Word Embeddings from flair.embeddings import FlairEmbeddings,WordEmbeddings,StackedEmbeddings,DocumentLSTMEmbeddings,DocumentRNNEmbeddings
In [46]:
# Create our WEmbeddings
word_embeddings = [FlairEmbeddings('news-forward-fast'),FlairEmbeddings('news-backward-fast')]
2020-10-04 13:40:09,332 https://flair.informatik.hu-berlin.de/resources/embeddings/flair/lm-news-english-forward-1024-v0.2rc.pt not found in cache, downloading to /tmp/tmpoq0qzh98
100%|██████████| 19689779/19689779 [00:00<00:00, 37035937.62B/s]
2020-10-04 13:40:09,930 copying /tmp/tmpoq0qzh98 to cache at /root/.flair/embeddings/lm-news-english-forward-1024-v0.2rc.pt 2020-10-04 13:40:09,977 removing temp file /tmp/tmpoq0qzh98
2020-10-04 13:40:10,619 https://flair.informatik.hu-berlin.de/resources/embeddings/flair/lm-news-english-backward-1024-v0.2rc.pt not found in cache, downloading to /tmp/tmpr4dnpuah
100%|██████████| 19689779/19689779 [00:00<00:00, 36642750.83B/s]
2020-10-04 13:40:11,225 copying /tmp/tmpr4dnpuah to cache at /root/.flair/embeddings/lm-news-english-backward-1024-v0.2rc.pt 2020-10-04 13:40:11,255 removing temp file /tmp/tmpr4dnpuah
In [62]:
# Document Embeddings document_embeddings = DocumentLSTMEmbeddings(word_embeddings,hidden_size=512,reproject_words=True,reproject_words_dimension=256)
/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:2: DeprecationWarning: Call to deprecated method __init__. (The functionality of this class is moved to 'DocumentRNNEmbeddings') -- Deprecated since version 0.4.
Building and Training
In [63]:
# Load NLP Pkgs from flair.models import TextClassifier from flair.trainers import ModelTrainer
In [64]:
# Classifier with CSV dataset clf = TextClassifier(document_embeddings,label_dictionary=label_dict_csv)
In [68]:
# Classifier with FastText Format clf2 = TextClassifier(document_embeddings,label_dictionary=label_dict_fst)
In [69]:
# Training # Init trainer = ModelTrainer(clf2,corpus_fst)
In [70]:
# Fit/Training with Dataset
trainer.train('data_fst/',max_epochs=2)
2020-10-04 14:07:16,724 ----------------------------------------------------------------------------------------------------
2020-10-04 14:07:16,727 Model: "TextClassifier(
(document_embeddings): DocumentLSTMEmbeddings(
(embeddings): StackedEmbeddings(
(list_embedding_0): FlairEmbeddings(
(lm): LanguageModel(
(drop): Dropout(p=0.25, inplace=False)
(encoder): Embedding(275, 100)
(rnn): LSTM(100, 1024)
(decoder): Linear(in_features=1024, out_features=275, bias=True)
)
)
(list_embedding_1): FlairEmbeddings(
(lm): LanguageModel(
(drop): Dropout(p=0.25, inplace=False)
(encoder): Embedding(275, 100)
(rnn): LSTM(100, 1024)
(decoder): Linear(in_features=1024, out_features=275, bias=True)
)
)
)
(word_reprojection_map): Linear(in_features=2048, out_features=256, bias=True)
(rnn): GRU(256, 512)
(dropout): Dropout(p=0.5, inplace=False)
)
(decoder): Linear(in_features=512, out_features=2, bias=True)
(loss_function): CrossEntropyLoss()
(beta): 1.0
(weights): None
(weight_tensor) None
)"
2020-10-04 14:07:16,729 ----------------------------------------------------------------------------------------------------
2020-10-04 14:07:16,731 Corpus: "Corpus: 2801 train + 935 dev + 932 test sentences"
2020-10-04 14:07:16,733 ----------------------------------------------------------------------------------------------------
2020-10-04 14:07:16,735 Parameters:
2020-10-04 14:07:16,737 - learning_rate: "0.1"
2020-10-04 14:07:16,741 - mini_batch_size: "32"
2020-10-04 14:07:16,743 - patience: "3"
2020-10-04 14:07:16,744 - anneal_factor: "0.5"
2020-10-04 14:07:16,745 - max_epochs: "2"
2020-10-04 14:07:16,746 - shuffle: "True"
2020-10-04 14:07:16,748 - train_with_dev: "False"
2020-10-04 14:07:16,751 - batch_growth_annealing: "False"
2020-10-04 14:07:16,752 ----------------------------------------------------------------------------------------------------
2020-10-04 14:07:16,756 Model training base path: "data_fst"
2020-10-04 14:07:16,758 ----------------------------------------------------------------------------------------------------
2020-10-04 14:07:16,761 Device: cpu
2020-10-04 14:07:16,763 ----------------------------------------------------------------------------------------------------
2020-10-04 14:07:16,765 Embeddings storage mode: cpu
2020-10-04 14:07:16,767 ----------------------------------------------------------------------------------------------------
2020-10-04 14:07:35,472 epoch 1 - iter 8/88 - loss 0.51544183 - samples/sec: 13.93 - lr: 0.100000
2020-10-04 14:07:53,353 epoch 1 - iter 16/88 - loss 0.48173103 - samples/sec: 14.33 - lr: 0.100000
2020-10-04 14:08:10,173 epoch 1 - iter 24/88 - loss 0.48178329 - samples/sec: 15.59 - lr: 0.100000
2020-10-04 14:08:26,789 epoch 1 - iter 32/88 - loss 0.48624196 - samples/sec: 15.42 - lr: 0.100000
2020-10-04 14:08:43,764 epoch 1 - iter 40/88 - loss 0.48142542 - samples/sec: 15.11 - lr: 0.100000
2020-10-04 14:09:00,269 epoch 1 - iter 48/88 - loss 0.46682192 - samples/sec: 15.52 - lr: 0.100000
2020-10-04 14:09:17,383 epoch 1 - iter 56/88 - loss 0.46152312 - samples/sec: 14.98 - lr: 0.100000
2020-10-04 14:09:34,412 epoch 1 - iter 64/88 - loss 0.46239550 - samples/sec: 15.27 - lr: 0.100000
2020-10-04 14:09:50,761 epoch 1 - iter 72/88 - loss 0.45929928 - samples/sec: 15.68 - lr: 0.100000
2020-10-04 14:10:07,515 epoch 1 - iter 80/88 - loss 0.45689389 - samples/sec: 15.30 - lr: 0.100000
2020-10-04 14:10:24,207 epoch 1 - iter 88/88 - loss 0.45517061 - samples/sec: 15.34 - lr: 0.100000
2020-10-04 14:10:24,341 ----------------------------------------------------------------------------------------------------
2020-10-04 14:10:24,343 EPOCH 1 done: loss 0.4552 - lr 0.1000000
2020-10-04 14:11:24,636 DEV : loss 0.4188002943992615 - score 0.8182
2020-10-04 14:11:25,024 BAD EPOCHS (no improvement): 0
saving best model
2020-10-04 14:11:25,103 ----------------------------------------------------------------------------------------------------
2020-10-04 14:11:42,894 epoch 2 - iter 8/88 - loss 0.37963553 - samples/sec: 14.60 - lr: 0.100000
2020-10-04 14:12:00,383 epoch 2 - iter 16/88 - loss 0.39962170 - samples/sec: 14.65 - lr: 0.100000
2020-10-04 14:12:17,873 epoch 2 - iter 24/88 - loss 0.39758716 - samples/sec: 14.66 - lr: 0.100000
2020-10-04 14:12:34,445 epoch 2 - iter 32/88 - loss 0.41368278 - samples/sec: 15.48 - lr: 0.100000
2020-10-04 14:12:52,102 epoch 2 - iter 40/88 - loss 0.41964307 - samples/sec: 14.77 - lr: 0.100000
2020-10-04 14:13:08,885 epoch 2 - iter 48/88 - loss 0.41549904 - samples/sec: 15.28 - lr: 0.100000
2020-10-04 14:13:25,909 epoch 2 - iter 56/88 - loss 0.40940068 - samples/sec: 15.05 - lr: 0.100000
2020-10-04 14:13:42,876 epoch 2 - iter 64/88 - loss 0.40874149 - samples/sec: 15.11 - lr: 0.100000
2020-10-04 14:13:59,836 epoch 2 - iter 72/88 - loss 0.41267412 - samples/sec: 15.10 - lr: 0.100000
2020-10-04 14:14:16,749 epoch 2 - iter 80/88 - loss 0.41082591 - samples/sec: 15.16 - lr: 0.100000
2020-10-04 14:14:33,315 epoch 2 - iter 88/88 - loss 0.41240300 - samples/sec: 15.46 - lr: 0.100000
2020-10-04 14:14:33,468 ----------------------------------------------------------------------------------------------------
2020-10-04 14:14:33,470 EPOCH 2 done: loss 0.4124 - lr 0.1000000
2020-10-04 14:15:32,670 DEV : loss 0.4321114122867584 - score 0.8214
2020-10-04 14:15:33,049 BAD EPOCHS (no improvement): 0
saving best model
2020-10-04 14:15:33,232 ----------------------------------------------------------------------------------------------------
2020-10-04 14:15:33,235 Testing using best model ...
2020-10-04 14:15:33,237 loading file data_fst/best-model.pt
2020-10-04 14:16:30,423 0.8541
2020-10-04 14:16:30,425
Results:
- F-score (micro) 0.8541
- F-score (macro) 0.7223
- Accuracy 0.8541
By class:
precision recall f1-score support
offensive 0.8965 0.9313 0.9136 772
non_offensive 0.5923 0.4813 0.5310 160
micro avg 0.8541 0.8541 0.8541 932
macro avg 0.7444 0.7063 0.7223 932
weighted avg 0.8443 0.8541 0.8479 932
samples avg 0.8541 0.8541 0.8541 932
2020-10-04 14:16:30,427 ----------------------------------------------------------------------------------------------------
Out[70]:
{'dev_loss_history': [0.4188002943992615, 0.4321114122867584],
'dev_score_history': [0.8182, 0.8214],
'test_score': 0.8541,
'train_loss_history': [0.4551706066863103, 0.4124030032279817]}
In [71]:
# Making Prediciton
# Load Saved Model and Predict
new_clf = TextClassifier.load('data_fst/best-model.pt')
2020-10-04 14:19:05,861 loading file data_fst/best-model.pt
In [72]:
from flair.data import Sentence
In [73]:
# Sample Sentence
ex1 = Sentence("That girl is a bitch")
ex2 = Sentence("This is a good material")
In [74]:
# Apply our model new_clf.predict(ex1)
In [75]:
ex1.labels
Out[75]:
[offensive (0.7436)]
In [76]:
new_clf.predict(ex2)
In [77]:
ex2.labels
Out[77]:
[non_offensive (0.7178)]
In [78]:
# Plot Loss Curve from flair.visual.training_curves import Plotter
In [79]:
plotter = Plotter()
plotter.plot_training_curves('data_fst/loss.tsv')
plotter.plot_weights('data_fst/weights.txt')
2020-10-04 14:23:07,751 ---------------------------------------------------------------------------------------------------- 2020-10-04 14:23:07,753 WARNING: No LOSS found for test split in this data. 2020-10-04 14:23:07,754 Are you sure you want to plot LOSS and not another value? 2020-10-04 14:23:07,755 ---------------------------------------------------------------------------------------------------- 2020-10-04 14:23:07,791 ---------------------------------------------------------------------------------------------------- 2020-10-04 14:23:07,792 WARNING: No F1 found for test split in this data. 2020-10-04 14:23:07,793 Are you sure you want to plot F1 and not another value? 2020-10-04 14:23:07,794 ----------------------------------------------------------------------------------------------------
No handles with labels found to put in legend.
Loss and F1 plots are saved in data_fst/training.png
Weights plots are saved in data_fst/weights.png
There is also a video tutorial that you can also check out for how it was done
Thanks For Your Time
Jesus Saves
By Jesse E.Agbe(JCharis)