
Machine Learning can be grouped into two based on the presence or absence of labels or target class. This gives us the main branches of supervised machine learning (where the dataset is provided with predefined labels) and unsupervised machine learning (where there are no labels given). The task of assigning labels to a dataset is normally done by human with some level of domain expertise. This can be a tedious task alongside the entire task of data cleaning and preparation. Remember that data is essential to Machine Learning, without which there will be no learning.
So how can we reduce and fix this challenge of laboriously labeling our datasets? Here is where Snorkel comes to play.
By the end of this tutorial, you will learn about
- The two approaches for creating ML Products
- How to Programmatically label unlabelled datasets using Snorkel
- The ins and outs of Snorkel
- etc
Let us start
Creating ML Products
The entire goal of machine learning is to create products that solve a particular problem just as humans would have done. In doing so we can approach it via two main views
- Data Centric View:
- Model Centric View:
These two approaches have span up two schools of thought in the field of ML.
Model Centric View:Those in the model centric view believe that the solution is mostly in the model, the different types of algorithms and how to produce performant ML models via hyper-parameter tuning. In this view, we keep the data constant and iterate on the model, the algorithms.
Data Centric View: With this approach, ML performance improvement is achieved by perfecting and augmenting the data being used. In this view we keep the algorithms nearly constant and iterate on the data being used.
So where does Snorkel comes to play, snorkel is a useful tool for data centric view of producing ML Products. It offers several functions for datasets labeling, data augmentation and data subset selection for the most important part of the datasets that is useful for feature engineering. In a way it can be useful for feature engineering.
Let us see how to use Snorkel for labeling of unlabeled datasets.
Labeling Datasets Using Snorkel
Snorkel has three main functions for working with datasets. These include
- Labeling Function: for labeling datasets
- Transformation Function: for data augmentation
- Slicing Function: for datasets sub selection
To label datasets we will see how to use the labeling function feature of snorkel to programmatically label an unlabeled datasets.
The basic workflow when working with snorkel is as below
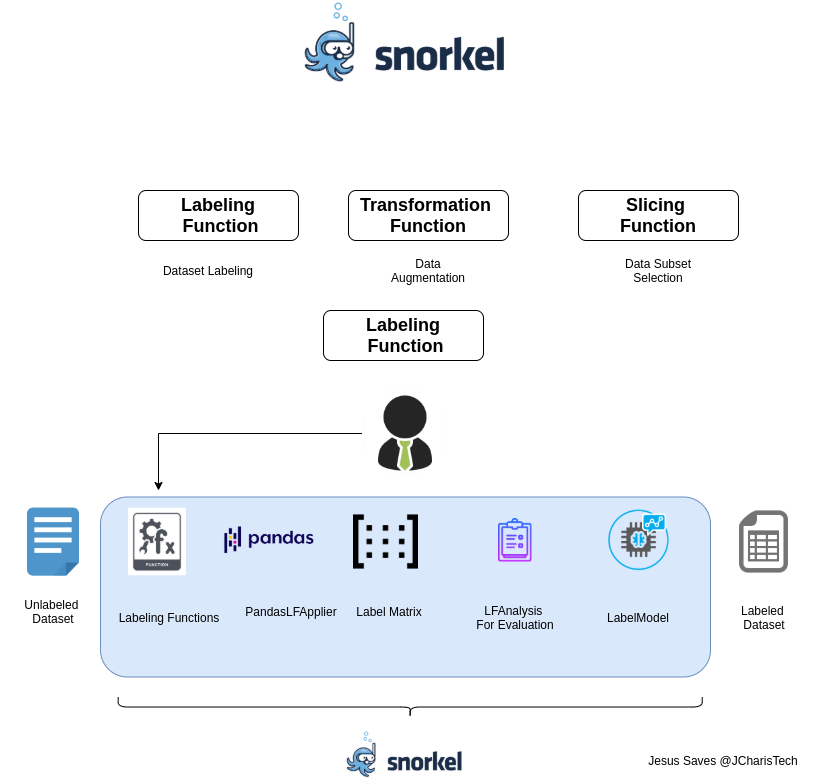
In our case we have some datasets consisting of questions and quotes. Our task as data scientists is to label them as questions or not or questions or quotes. By normal intuition, we know that questions usually follow a pattern and have some keywords such as what,why,when,where,who and which. These are the 5Ws. There are also questions with the keyword “How”. This is the basics of most questions. Moreover most questions if not all, ends with a question mark (‘?’). Hence we can use this knowledge as heuristics to design a function to label our dataset.
Snorkel provides a labeling_function decorator that we can wrap around our functions to enable us label tons of data easily. Let us install Snorkel first and then move from there
# Installation pip install snorkel
This labeling function can take in functions designed for
- Keyword Lookup
- Pattern Lookup
- Regex Lookup
- 3rd Party Tools eg. spacy, textblob,etc
- etc
We will explore how to use these functions on our task. Let us start with our dataset
Data Preparation
data = "What would you name your boat if you had one? ", "What's the closest thing to real magic? ", "Who is the messiest person you know? ", "What will finally break the internet? ", "What's the most useless talent you have? ", "What would be on the gag reel of your life? ", "Where is the worst smelling place you've been?", "What Secret Do You Have That No One Else Knows Except Your Sibling/S?" "What Did You Think Was Cool Then, When You Were Young But Isn’t Cool Now?" "When Was The Last Time You Did Something And Regret Doing It?" "What Guilty Pleasure Makes You Feel Alive?" "Any fool can write code that a computer can understand. Good programmers write code that humans can understand.", "First, solve the problem. Then, write the code.", "Experience is the name everyone gives to their mistakes.", " In order to be irreplaceable, one must always be different", "Java is to JavaScript what car is to Carpet.", "Knowledge is power.", "Sometimes it pays to stay in bed on Monday, rather than spending the rest of the week debugging Monday’s code.", "Perfection is achieved not when there is nothing more to add, but rather when there is nothing more to take away.", "Ruby is rubbish! PHP is phpantastic!", " Code is like humor. When you have to explain it, it’s bad.", "Fix the cause, not the symptom.", "Optimism is an occupational hazard of programming: feedback is the treatment. " , "When to use iterative development? You should use iterative development only on projects that you want to succeed.", "Simplicity is the soul of efficiency.", "Before software can be reusable it first has to be usable.", "Make it work, make it right, make it fast.", "Programmer: A machine that turns coffee into code.", "Computers are fast; programmers keep it slow.", "When I wrote this code, only God and I understood what I did. Now only God knows.", "A son asked his father (a programmer) why the sun rises in the east, and sets in the west. His response? It works, don’t touch!", "How many programmers does it take to change a light bulb? None, that’s a hardware problem.", "Programming is like sex: One mistake and you have to support it for the rest of your life.", "Programming can be fun, and so can cryptography; however, they should not be combined.", "Programming today is a race between software engineers striving to build bigger and better idiot-proof programs, and the Universe trying to produce bigger and better idiots. So far, the Universe is winning.", "Copy-and-Paste was programmed by programmers for programmers actually.", "Always code as if the person who ends up maintaining your code will be a violent psychopath who knows where you live.", "Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.", "Algorithm: Word used by programmers when they don’t want to explain what they did.", "Software and cathedrals are much the same — first we build them, then we pray.", "There are two ways to write error-free programs; only the third works.", "If debugging is the process of removing bugs, then programming must be the process of putting them in.", "99 little bugs in the code. 99 little bugs in the code. Take one down, patch it around. 127 little bugs in the code …", "Remember that there is no code faster than no code.", "One man’s crappy software is another man’s full-time job.", "No code has zero defects.", "A good programmer is someone who always looks both ways before crossing a one-way street.", "Deleted code is debugged code.", "Don’t worry if it doesn’t work right. If everything did, you’d be out of a job.", "It’s not a bug — it’s an undocumented feature.", "It works on my machine.", "It compiles; ship it.", "There is no Ctrl-Z in life.", "Whitespace is never white.", "What’s your favorite way to spend a day off?", "What type of music are you into?", "What was the best vacation you ever took and why?", "Where’s the next place on your travel bucket list and why?", "What are your hobbies, and how did you get into them?", "What was your favorite age growing up?", "Was the last thing you read?", "Would you say you’re more of an extrovert or an introvert?", "What's your favorite ice cream topping?", "What was the last TV show you binge-watched?", "Are you into podcasts or do you only listen to music?", "Do you have a favorite holiday? Why or why not?", "If you could only eat one food for the rest of your life, what would it be?", "Do you like going to the movies or prefer watching at home?", "What’s your favorite sleeping position?", "What’s your go-to guilty pleasure?", "In the summer, would you rather go to the beach or go camping?", "What’s your favorite quote from a TV show/movie/book?", "How old were you when you had your first celebrity crush, and who was it?", "What's one thing that can instantly make your day better?", "Do you have any pet peeves", "What’s your favorite thing about your current job?", "What annoys you most?", "What’s the career highlight you’re most proud of?", "Do you think you’ll stay in your current gig awhile? Why or why not?", "What type of role do you want to take on after this one?", "Are you more of a work to live or a live to work type of person?", "Does your job make you feel happy and fulfilled? Why or why not?", "How would your 10-year-old self react to what you do now?", "What do you remember most about your first job?", "How old were you when you started working?", "What’s the worst job you’ve ever had?", "What originally got you interested in your current field of work?", "Have you ever had a side hustle or considered having one?", "What’s your favorite part of the workday?", "What’s the best career decision you’ve ever made?", "What’s the worst career decision you’ve ever made?", "Do you consider yourself good at networking?]
We will then shuffle the data and convert it to a dataframe using random and pandas respectively.
# Load EDA Pkgs
import pandas as pd
import random
from sklearn.model_selection import train_test_split
# Shuffle Dataset
random.shuffle(data)
# Convert to DataFrame
df = pd.DataFrame({'sentences':data})
df.head()
Next we will split the datasets into train and test or you can ignore this step and use all the datasets.
df_train, df_test = train_test_split(df, train_size = 0.5)
Next we will define some constants for the labels we want to use, these will include 0,1 and -1 for where we want our function to abstain.
# Define Constants ABSTAIN = -1 QUOTE = 0 QUESTION = 1
Let us define our functions and decorate them with Snorkel’s labeling function and then apply them
# Import Pkgs
from snorkel.labeling import labeling_function,PandasLFApplier,LFAnalysis
## Create Labeling Functions
# Using Keyword Lookup: Method 1
@labeling_function()
def lf_keyword_lookup(x):
keywords = "what|why|when|how|where|which|who|whose".split("|")
return QUESTION if any(word in x.sentences.lower() for word in keywords) else ABSTAIN
# Keyword lookup : Method 2
@labeling_function()
def lf_contains_questions(x):
# Return a label of QUESTION if "what|why|when|how|where|which|who|whose" in sentence text, otherwise QUOTE
for word in "what|why|when|how|where|which|who|whose".split("|"):
if word in x.sentences.lower():
return QUESTION
else:
return ABSTAIN
# Regex Lookup
@labeling_function()
def lf_regex_ends_with_question_mark(x):
return QUESTIONS if re.search(r"*.*?", x.sentences, flags=re.I) else ABSTAIN
Using PandasLFApply we will generate a matrix per the number of functions. This matrix is called a Label Matrix. With this we can now check for the coverage – how many datapoints meet our labeling function. How many were labeled accordingly per each individual function.
## Apply on Pandas lfs = [lf_keyword_lookup,lf_contains_questions,lf_regex_ends_with_question_mark] applier = PandasLFApplier(lfs=lfs) L_train = applier.apply(df=df_train)
To evaluate how good our labeling_function is we can use the LFAnalysis class from snorkel as below
# Find percentage of dataset that was labels [Coverage]
coverage_questions, coverage_keyword,coverage_5w = (L_train != ABSTAIN).mean(axis=0)
print(f"questions coverage: {coverage_questions * 100:.1f}%")
print(f"keyword coverage: {coverage_keyword * 100:.1f}%")
print(f"5w coverage: {coverage_5w * 100:.1f}%")
### Evaluate Labeling Performance
LFAnalysis(L=L_train, lfs=lfs).lf_summary()
Now let us build a model using the LabelModel and use it to predict what each sentence is
# Build Model label_model = LabelModel(cardinality=2, verbose=True) label_model.fit(L_train=L_train, n_epochs=500, log_freq=100, seed=123)
After building the label_model we can use it on our unlabeled datasets to make predictions as below
# Make Prediction df_train["label"] = label_model.predict(L=L_train, tie_break_policy="abstain")
There are also other functions that we can use in Snorkel, but we will end here since our main goal was to use Snorkel label_function to label an unlabelled data.
To check for the accuracy of the LabelModel , you can compare it with the test dataset if it is labeled. However our entire datasets was not labelled already so we skipped,
# label_model_acc = label_model.score(L=L_test, Y=Y_test, tie_break_policy="random")[
# "accuracy"
# ]
# print(f"{'Label Model Accuracy:':<25} {label_model_acc * 100:.1f}%")
That is so cool, we have seen how to use Snorkel to do transformation an unlabeled data to a labeled datasets.
You can also check out the video tutorial below.
Thanks for Your Attention
Jesus Saves
Jesse E.Agbe(JCharis)