
Streamlit is Awesome!!!. In this post, we will build a simple Natural Language Processing App(NLP) app with streamlit in python. Our app will be useful for some interesting aspect of NLP such as:
- Tokenization and Lemmatization of Text
- Named Entity Recognition
- Sentiment Analysis
- Text Summarization
We will be using the wonderful SpaCy library for our tokenization and our named entity recognition. For our sentiment analysis we will use TextBlob, a simple but powerful package for sentiment analysis that gives both the polarity and the subjectivity of sentiment. Moreover we will utilize Gensim and Sumy for our text summarization.
Finally,will add some awesomeness to our NLP app using Streamlit.
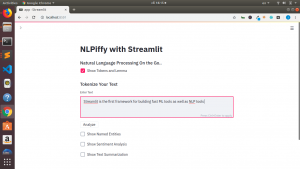
Let us begin.
Installation of the Required Packages
# NLP Pkgs pip install spacy textblob # Summarization Pkgs pip install gensim sumy # Awesome Pkg pip install streamlit
We will create a file app.py where all our code will be. And then run our app in our terminal using
streamlit run app.py
We will place all our codes inside a main function and run it as such.
Below is the entire code for our NLP app
import streamlit as st
import os
# NLP Pkgs
from textblob import TextBlob
import spacy
from gensim.summarization import summarize
# Sumy Pkg
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.lex_rank import LexRankSummarizer
# Sumy Summarization
def sumy_summarizer(docx):
parser = PlaintextParser.from_string(docx,Tokenizer("english"))
lex_summarizer = LexRankSummarizer()
summary = lex_summarizer(parser.document,3)
summary_list = [str(sentence) for sentence in summary]
result = ' '.join(summary_list)
return result
# Function For Analysing Tokens and Lemma
@st.cache
def text_analyzer(my_text):
nlp = spacy.load('en')
docx = nlp(my_text)
# tokens = [ token.text for token in docx]
allData = [('"Token":{},\n"Lemma":{}'.format(token.text,token.lemma_))for token in docx ]
return allData
# Function For Extracting Entities
@st.cache
def entity_analyzer(my_text):
nlp = spacy.load('en')
docx = nlp(my_text)
tokens = [ token.text for token in docx]
entities = [(entity.text,entity.label_)for entity in docx.ents]
allData = ['"Token":{},\n"Entities":{}'.format(tokens,entities)]
return allData
def main():
""" NLP Based App with Streamlit """
# Title
st.title("NLPiffy with Streamlit")
st.subheader("Natural Language Processing On the Go..")
# Tokenization
if st.checkbox("Show Tokens and Lemma"):
st.subheader("Tokenize Your Text")
message = st.text_area("Enter Text","Type Here ..")
if st.button("Analyze"):
nlp_result = text_analyzer(message)
st.json(nlp_result)
# Entity Extraction
if st.checkbox("Show Named Entities"):
st.subheader("Analyze Your Text")
message = st.text_area("Enter Text","Type Here ..")
if st.button("Extract"):
entity_result = entity_analyzer(message)
st.json(entity_result)
# Sentiment Analysis
if st.checkbox("Show Sentiment Analysis"):
st.subheader("Analyse Your Text")
message = st.text_area("Enter Text","Type Here ..")
if st.button("Analyze"):
blob = TextBlob(message)
result_sentiment = blob.sentiment
st.success(result_sentiment)
# Summarization
if st.checkbox("Show Text Summarization"):
st.subheader("Summarize Your Text")
message = st.text_area("Enter Text","Type Here ..")
summary_options = st.selectbox("Choose Summarizer",['sumy','gensim'])
if st.button("Summarize"):
if summary_options == 'sumy':
st.text("Using Sumy Summarizer ..")
summary_result = sumy_summarizer(message)
elif summary_options == 'gensim':
st.text("Using Gensim Summarizer ..")
summary_result = summarize(rawtext)
else:
st.warning("Using Default Summarizer")
st.text("Using Gensim Summarizer ..")
summary_result = summarize(rawtext)
st.success(summary_result)
st.sidebar.subheader("About App")
st.sidebar.text("NLPiffy App with Streamlit")
st.sidebar.info("Cudos to the Streamlit Team")
st.sidebar.subheader("By")
st.sidebar.text("Jesse E.Agbe(JCharis)")
st.sidebar.text("Jesus saves@JCharisTech")
if __name__ == '__main__':
main()
You can also check the entire video tutorial here.
Streamlit is awesome!!. With just this simple code we have been able to build something awesome. Great work by the Streamlit Team.
Thanks For Your Time
Jesus Saves
By Jesse E.Agbe(JCharis)
OSError: [E050] Can’t find model ‘en’. It doesn’t seem to be a shortcut link, a Python package or a valid path to a data directory.
Traceback:
File “/opt/anaconda3/lib/python3.7/site-packages/streamlit/ScriptRunner.py”, line 311, in _run_script
exec(code, module.__dict__)
File “/Users/sauce_god/Documents/Programs/Streamlit/nlp-app/app.py”, line 41, in
main()
File “/Users/sauce_god/Documents/Programs/Streamlit/nlp-app/app.py”, line 28, in main
nlp_result = text_analyzer(message)
File “/Users/sauce_god/Documents/Programs/Streamlit/nlp-app/app.py”, line 10, in text_analyzer
nlp = spacy.load(‘en’)
File “/opt/anaconda3/lib/python3.7/site-packages/spacy/__init__.py”, line 30, in load
return cli_info(model, markdown, silent)
File “/opt/anaconda3/lib/python3.7/site-packages/spacy/util.py”, line 169, in load_model
data_dir = ‘%s_%s-%s’ % (meta[‘lang’], meta[‘name’], meta[‘version’])
Hi Braucuss, you will have to download the ‘en’ model for spacy
Method1
python -m spacy download en
Method 2
python -m spacy download’en_core_web_sm
nlp = spacy.load(‘en_core_web_sm’)
Hope it helps
Thanks, Jesse. The second method worked.
Glad it worked, Brauccus
Hello there, just became aware of your blog through Google, and found that it’s really informative. I am gonna watch out for brussels. I抣l appreciate if you continue this in future. Many people will be benefited from your writing. Cheers!
Hi Jesse! Thanks for sharing your code! My spacy package is not working, maybe you have a hint on why?
“No module named spacy” but it’s installed.
Idk
Hi Paola. Can you try reinstall it again or use a virtual env eg virtualenv or pipenv or conda.
In case none of them work you can try Google Colab which is free with your gmail account.
Hope it helps.
Hello. Thank you for this interesting article.
Can we build this kind of app to upload a word/pdf file and extract some information (to build a table with that) ?
Yes Rone, it is possible to build such an app. You can check the Youtube Channel for such implementation.
Hope this helps